Why One Data Vendor Isn't Enough: The Case for Multi-Source Person-level Website Identity Resolution
Here's a question that should keep every B2B marketer up at night: What if the website visitor leads you're seeing are only a fraction of the total number of leads you should be seeing for every 100 site visitors?
Most companies invest heavily to drive traffic to their website - content programs, paid campaigns, SEO, events. That investment pays off. Visitors arrive. They browse product pages, read case studies, compare pricing. And then 98% of them leave without ever filling out a form. Anonymous. Gone.
Person-level Website Visitor Identity resolution - the technology that de-anonymizes those visitors and connects them to real people at real companies - has become the go-to solution for this problem. But here's what most teams get wrong: they pick a provider that uses a single de-anonymization data source, plug it in, and assume they're covered.
They're not. Not even close.
The Blind Spot You Don't Know You Have
Every person-level website visitor identity resolution data vendor works differently. Each one draws from its own proprietary data partnerships, cookie graphs from third party data providers, device networks, and matching algorithms. The result? Each website visitor de-anonymization vendor sees a different slice of your traffic. No single de-anonymization data source - no matter how large or well-known - captures the complete picture.
This isn't a theoretical limitation. It's a measurable one. And the data we're about to walk through makes the scale of the problem impossible to ignore.
The Data: 11 Days, 3 Sources, 26,728 Leads
We ran a controlled analysis over an 11-day period, feeding the same pool of anonymous website traffic through three leading person-level website visitor identity resolution providers simultaneously. The goal was simple: measure what each source sees - and what it misses.
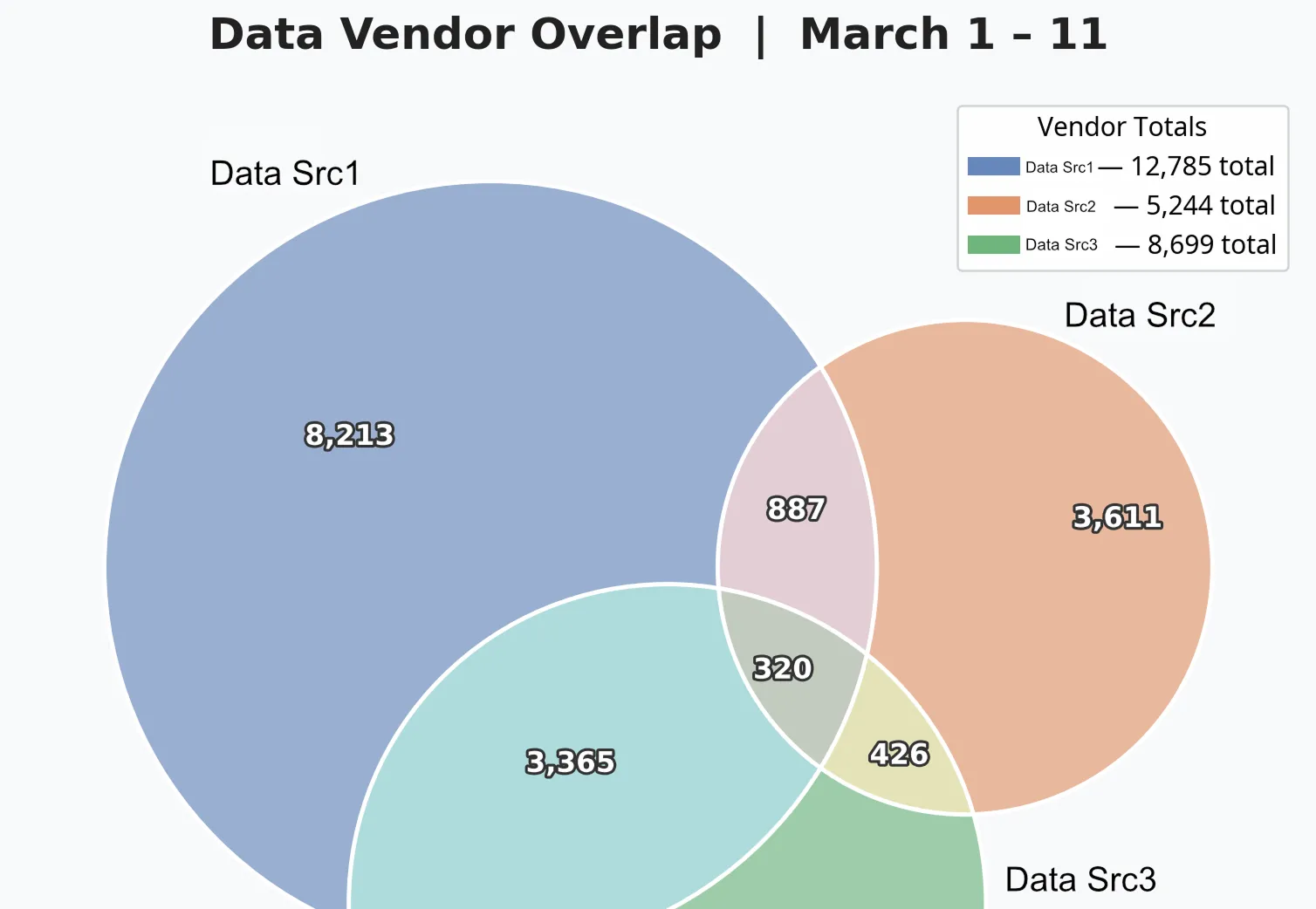
Here's the Venn diagram of the results:
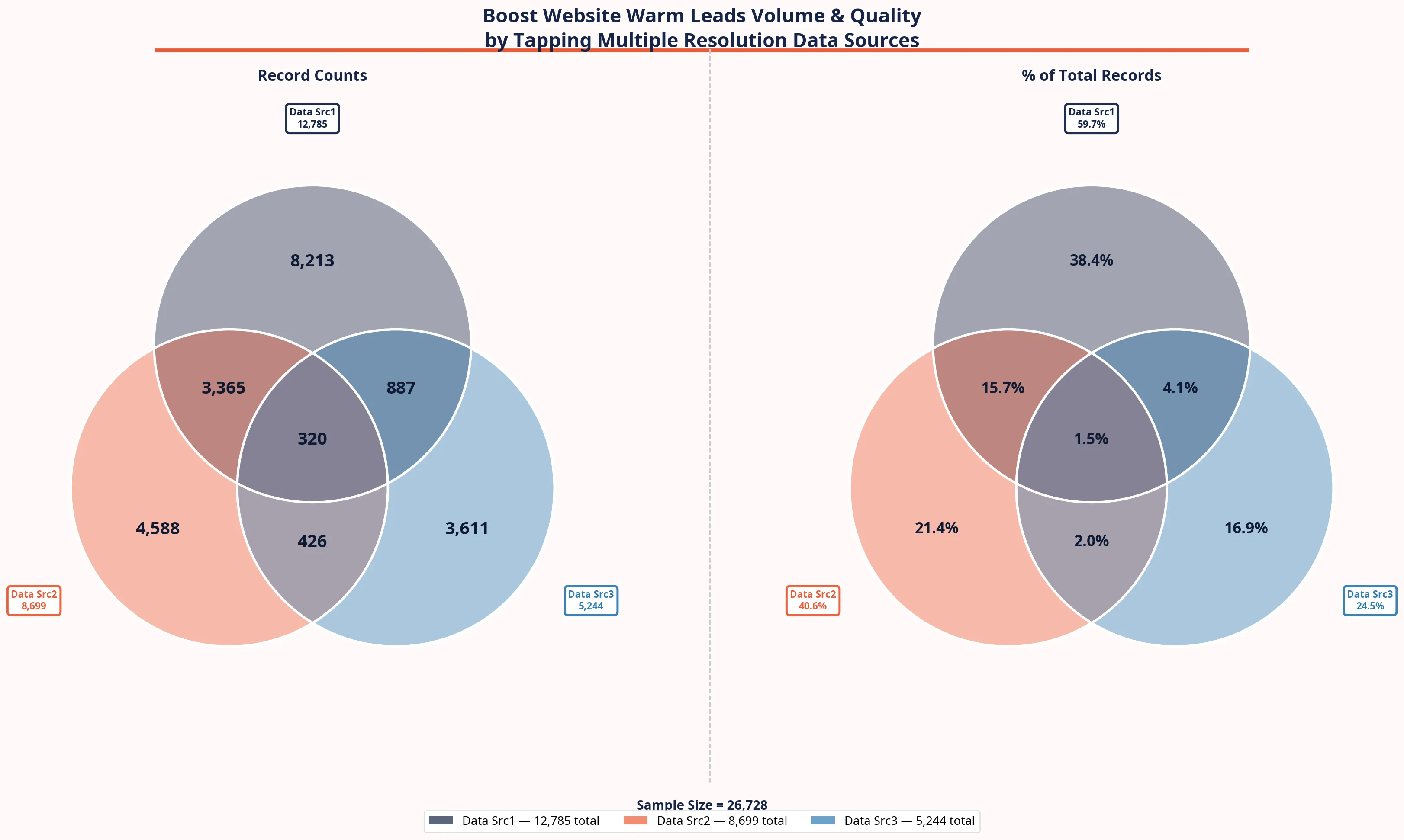
And here's the summary table:
| Data Source | Total Records Identified | Exclusive Records (Not Found by Others) |
| Resolution Data Source 1 | 12,785 | 8,213 |
| Resolution Data Source 2 | 8,699 | 4,588 |
| Resolution Data Source 3 | 5,244 | 3,611 |
Read those "Exclusive Records" numbers carefully. Those aren't edge cases. They're the core of the problem.
If you're running Source 3 alone, you're identifying 5,244 leads. Solid number. But you're completely blind to 8,213 leads that only Source 1 sees, and another 4,588 that only Source 2 sees. That's over 12,800 real, identifiable prospects - people who visited your website, showed intent, and were invisible to your sales team.
The combined, deduplicated total across all three website visitor resolution data sources? 26,728 unique leads. That's a 410% increase over what Source 3 alone would have delivered.
This isn't an argument about which website de-anonymization vendor is "better." It's a structural reality: every vendor has blind spots, and those blind spots are different. The only way to close them is to layer sources together.
Where the Real Quality Story Hides
Volume is the headline. But the more strategic insight is buried in the overlaps - the leads that two or three sources independently identified from the same website traffic.
Think about what that means: when multiple website de-anonymization data vendors, using completely independent data networks and matching methodologies, arrive at the same identity for the same anonymous visitor, the probability that the identification is accurate goes up dramatically. It's independent corroboration.
Here's what the overlap data showed:
320 leads were identified by all three sources - triple-verified. These are your highest-confidence records. The likelihood of data accuracy here is exceptionally high.
3,365 leads were identified by Source 1 and Source 2.
887 leads were identified by Source 1 and Source 3.
426 leads were identified by Source 2 and Source 3.
That's nearly 5,000 dual-verified leads on top of the 320 triple-verified ones. These aren't just names in a spreadsheet. They're prospects where you can have high confidence in the name, title, company, and contact information - because multiple independent systems agree.
This overlap data gives you something that no single vendor can provide on its own: a built-in quality signal that requires zero additional spend on data enrichment or verification tools.
Turning Data into Action: A Tiered Engagement Framework
The multi-source approach doesn't just give you more leads and better data. It gives you a natural prioritization framework - a way to route leads based on data confidence, so your team's effort matches the opportunity.
The beauty of this framework is that it's self-reinforcing. As you continue running multi-source resolution, new traffic continuously flows into the model, leads get re-verified, and your confidence scoring improves over time.
How to Choose Complementary Data Sources
The goal isn't to stack vendors indiscriminately. It's to combine sources that are genuinely complementary - each one covering ground the others miss, with enough overlap to enable corroboration.
Here's what to evaluate when building your data stack:
Exclusive coverage. What percentage of a source's records are unique to that source? This is the clearest measure of incremental value. In our analysis, Source 1 delivered 8,213 exclusive records - leads that neither of the other two sources found. That's the kind of additive value you're looking for.
Overlap rate. A sweet spot of roughly 20-40% overlap with your existing sources is ideal. Too little overlap means you lose the quality-scoring benefit of corroboration. Too much overlap means you're paying for redundancy.
Data freshness. How frequently does the vendor update its data? Stale contact information - wrong titles, old email addresses, people who've changed companies - is one of the biggest silent killers of outbound campaign performance.
Depth of enrichment. Beyond name and email, what firmographic and technographic data does the source provide? Company size, industry, tech stack, funding stage - the richer the profile, the more precisely you can target and personalize.
In the dataset we analyzed, Source 1 served as the clear anchor: highest total volume, highest exclusive coverage, and the largest contributor to the overlap pool. Sources 2 and 3 each brought meaningful incremental coverage while also reinforcing the quality of the shared records. That's the model to aim for.
The Bottom Line
Relying on a single identity resolution vendor is like fishing with one net in a lake that requires three. You'll catch something. But you'll miss most of what's there.
The data from our analysis makes two things unambiguous:
Multi-source website visitor identity resolution dramatically expands your addressable lead pool. In this case, from 5,244 to 26,728 - a 410% increase. Those aren't theoretical leads. They're real people who visited your site, expressed interest through their behavior, and were identifiable - just not by a single source alone.
Multi-source visitor resolution builds quality into the data itself. The overlap between sources creates a natural confidence tier that lets you prioritize outreach, allocate resources efficiently, and stop wasting your sales team's time on low-confidence records.
In a market where every pipeline dollar is being scrutinized, this isn't an optimization. It's a structural advantage. The companies that see more, verify more, and act faster on their website traffic will outperform those that don't.
The question isn't whether to adopt a multi-source strategy. It's how quickly you can get one running.

Mani Iyer
Serial entrepreneur and B2B GTM expert with 34+ years of experience building and scaling technology businesses. Founded Kwanzoo as an AI-powered Go-to-Market automation platform after previously founding a software company acquired by Oracle/PeopleSoft.